![[object Object]](/_next/image?url=https%3A%2F%2Fcdn.sanity.io%2Fimages%2Fei1axngy%2Fproduction%2Fcc5ab2d63daeea476490218d4e41b58074e8d535-2147x2147.jpg&w=256&q=75)
by Dr Alexander Mead
Updated 20 September 2023
Introducing Active Learning with twinLab
![[object Object]](/_next/image?url=https%3A%2F%2Fcdn.sanity.io%2Fimages%2Fei1axngy%2Fproduction%2F4dd79be3cc30891df902b3865f3feb92c5f169bf-1174x407.png&w=2048&q=75)
Active Learning is a powerful statistical technique that augments the efficiency and effectiveness of machine-learning models. Recognising that our user base includes engineers, who may not be intimately familiar with machine learning or Bayesian statistics, this post will elucidate the concept and practical application of Active Learning in a manner that is both comprehensive and accessible.
Active Learning: A Brief Introduction
Requiring more data to train a machine-learning model is a problem that is commonly encountered by data scientists and engineers. However, we then need to make decisions about exactly which new data should be collected in order to improve the model most effectively. For example, imagine we were training a machine-learning model to learn the distribution of pollutants across a city. We could take measurements at a large number of locations across the city and combine these all into one model. This would work, but it may be expensive to take the measurements and train the model. Instead, if we could show the model a representative set of pollutant measurements, with more measurements over highly-polluted areas and over areas where the level of pollution was changing rapidly, we could train the model more efficiently: We train the model with fewer data points while still achieving the desired accuracy, saving us time and money.
Active Learning is a subset of machine learning techniques that prioritises the use of selective high-impact data during the training process. Unlike traditional machine learning methods, which often require extensive datasets for training, Active Learning identifies and utilises only the most informative data points. This targeted approach results in an accurate model trained with less data.
The Relevance of Active Learning for Engineering Applications
-
Data Efficiency: One of the most formidable challenges in deploying machine-learning models is the collection and curation of large datasets. Active Learning mitigates this issue by achieving higher accuracy with fewer data points.
-
Time Economy: By concentrating solely on high-impact data, Active Learning reduces the computational time required for training, thereby accelerating project timelines.
-
Resource Optimization: The reduced demand for computational power and storage not only translates to cost savings but also aligns well with sustainability objectives.
Operational Framework of Active Learning within twinLab
In twinLab, we have made Active Learning simple to use, requiring no specialised expertise in machine learning or statistics.
import twinlab as tl
model = "pre_trained_model"
number_of_new_data_points = 5
tl.active_learn_campaign(model, number_of_new_datapoints)
Given a pre-trained model we have requested the locations of 5 new data-points. Given that our twinLab model quantifies its own uncertainty, the Active Learning capability calculates the locations of the 5 new data points that would most effectively reduce that uncertainty. This improves the fit of the model the most for the lowest data cost.
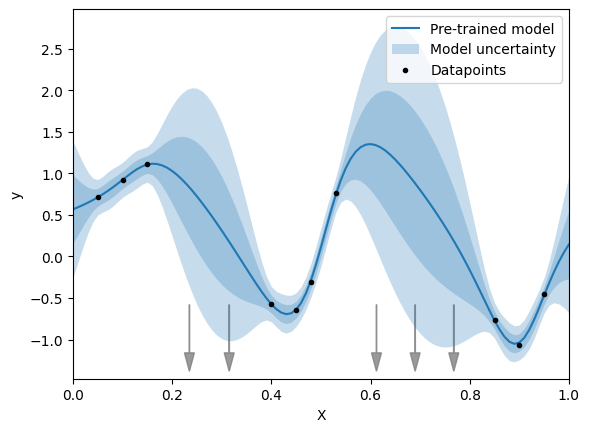
Figure 1: A simple example of Active Learning
Fig. 1: A twinLab model has initially been trained using the 9 black data points. The average prediction from the trained model and the associated uncertainty bounds are shown in blue. The user selects Active Learning to identify the next 5 points that will collectively reduce uncertainty and improve the model the most. These data points are shown via the grey arrows, two between and , and three between and . In this simple example it is easy for the user to identify points on the axis where additional data points would help reduce the overall uncertainty. However, in realistic high-dimensional problems this is not possible, but twinLab can still be relied on in these situations, which we demonstrate in our Case Study below.
Active Learning can also be implemented in an "Active Learning loop", where new data are measured and a new model is then trained. Active Learning is then used again and the cycle is repeated until the desired accuracy is achieved. In cases where the data are generated via simulation this can be done without any human input, with the model itself deciding which simulations should be run in order to improve itself the most effectively.
import pandas as pd
import twinlab as tl
# Load original data and training parameters
data = pd.load_csv("my_data.csv")
params = json.loads("training_parameters.json")
# Active Learning loop
for i in range(10):
tl.upload_dataset(data, "my_data")
tl.train_campaign(params, "my_model")
X = tl.active_learn_campaign("my_model", 1)
y = complicated_simulation(X)
data.append({"X": X, "y": y})
Here we have taken some initial data and trained a model. We then set up an Active Learning loop of 10 iterations. Areas with poorer data coverage are identified, triggering new simulations to be run such that the model then updates itself automatically and sequentially.
Case Study: Radioactive contamination
A more realistic example of Active Learning in action can be based on a project that digiLab was involved in. Consider the case of nuclear decommissioning, where we are interested in knowing the level of radiation across land around a nuclear power station. In this case, to measure the level of radiation in soil requires engineers to drive to different points on the site and to then take expensive measurements of soil samples. From these individual samples an approximate map can be made of radioactivity levels across the site, but the fidelity of the map will vary according to both the location of samples that have already been taken and also the variability trends of radiation levels across the site, which would not be known in advance.
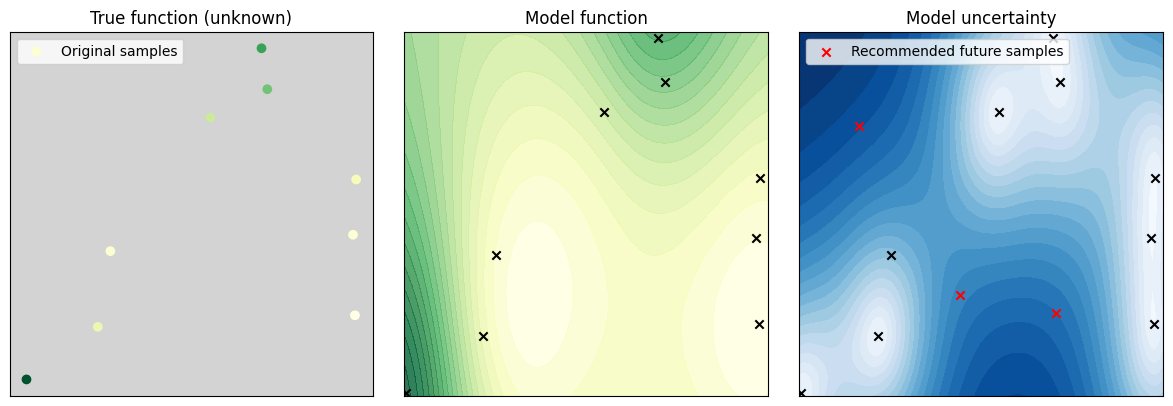
Figure 2: A more complicated example of active learning, where we consider radiation levels across a hypothetical site
Fig. 2: In the left-hand panel we show the locations of the first set of measurements taken of the radiation level. The level of contamination is indicated by the colour of the data points. We would like to know the radiation level across the whole site, but we only have access to measurements at a limited number of locations. Based on these measurements, the central panel shows the best estimate from the twinLab model of the true radiation level. The right-hand panel shows the uncertainty of the model, which is largest where there are no data points, but also where there are predicted to be larger changes in the radiation level. This uncertainty is what twinLab Active Learning uses to decide where to take new measurements. In this case, we have decided to make 3 new measurements, and twinLab Active Learning has determined the 3 best locations at which to make these, marked by the red crosses.
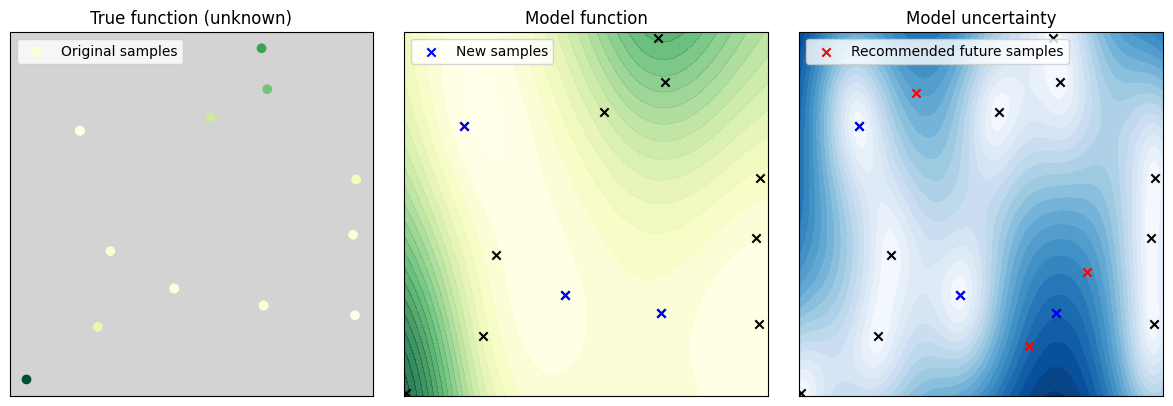
Figure 3: The same as Fig. 2 updated with new data
Fig. 3: We show the result of updating the model using data taken at the red crosses from Fig. 2. We see that the updated model has an updated map and that the uncertainty across the site (right-hand panel) is now smaller. This process can be repeated until the model is sufficiently accurate for the application at hand.
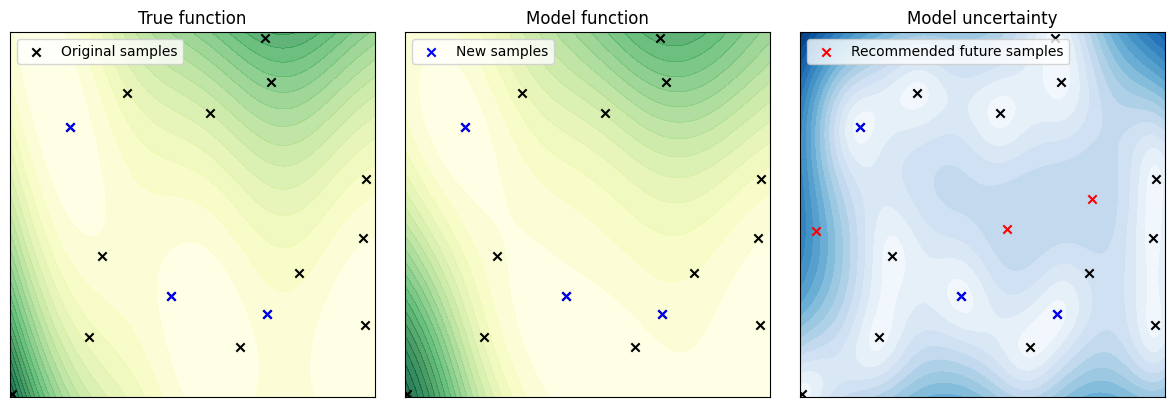
Fig. 4: The same as Fig. 3, but updated with new data and with the true function revealed
Fig. 4: One further application of the Active Learning cycle. Here the true function has been revealed in the left-hand panel, which can be compared to the twinLab estimate in the central panel.
Conclusion
Modeling real-world scenarios can be slow and expensive either because of the time and cost of collecting the data or because of the time and cost of running that model. Active learning is a technique that can be used to reduce this time and expense. Recognising the value that this capability has for our users, it has now been made available in twinLab.
Interested in how active learning and using surrogate models reduce design cycles in your workflow?
Featured Posts
If you found this post helpful, you might enjoy some of these other news updates.
Python In Excel, What Impact Will It Have?
Exploring the likely uses and limitations of Python in Excel

Richard Warburton
Large Scale Uncertainty Quantification
Large Scale Uncertainty Quantification: UM-Bridge makes it easy!

Dr Mikkel Lykkegaard
Expanding our AI Data Assistant to use Prompt Templates and Chains
Part 2 - Using prompt templates, chains and tools to supercharge our assistant's capabilities

Dr Ana Rojo-Echeburúa