![[object Object]](/_next/image?url=https%3A%2F%2Fcdn.sanity.io%2Fimages%2Fei1axngy%2Fproduction%2Ff83f8e24d1fb84d1211763941d7874ed6b2a2da8-281x285.jpg&w=256&q=75)
by Prof Tim Dodwell
Updated 28 April 2023
Rebalancing your data with the Synthetic Minority Oversampling Technique (aka SMOTE)
![[object Object]](/_next/image?url=https%3A%2F%2Fcdn.sanity.io%2Fimages%2Fei1axngy%2Fproduction%2Fdfed129af717a8006248fcd8cf720416260bcb8f-800x459.jpg&w=2048&q=75)
In classification problems, imbalanced datasets are really common. This causes particular problems when building good machine learning classifiers. If we don't rebalance the data, we see that models are particularly susceptible to giving false negative results - this is where the algorithm wrongly classifies a 'True' result and a 'False'. In this explainer, we look at a method to help rebalance imbalanced datasets called SMOTE - the Synthetic Minority Oversample Technique. We walk you through imbalanced data sets in classification, give an overview of the approach and then dig into some code so you can see it working in practice on real-world data. Let's get started.
Classification Tasks in Machine Learning
A central task in machine learning is classification. Classification is a supervised learning challenge, where we have labelled data and we want a `learning system' to be able to take new input data and correctly classify the outcome
When talking about classification and supervised learning models in the Foundations of Machine Learning Course I am doing for the AI in the Wild series, I always use the slightly silly example "Is this a picture of a Cat?" - the cornerstone problem in computer vision benchmarks!
Ok, this is a rather silly example, and there are lots of important classification problems where Machine Learning models are making a transformative difference. Let's look at two.
- Medical Diagnostic - This has particularly been the case for the classification of medical images for conditions like skin and breast cancer (more on this here). Examples of medical images are given as inputs, along with the diagnosis as the labelled output. AI algorithms have been shown to outperform experienced medical practitioners at this particular task, and importantly the building algorithm allows widespread services to be offered to places around the world where such skilled medical services are traditionally widely available. AMAZING.
- Fault Detection in Engineering Systems - Engineering systems are designed to last, and therefore thankfully failure events are rare in well-engineered systems. This is a real challenge in data science. Having said this machine learning technology is now increasingly being used to detect when an engineering system has a fault, or even better than that, predict prior to it failing.
Other applications might include fraud detection, spam filtering in emails .
Figure 1. There are many applications in which we have imbalanced dataset. it is vital to apply machine learning algorithms like smote to get good performance when predicting rare outcomes (minority class samples)
Dealing with an Imbalanced Dataset
What you will notice about each of the examples above is, that thankfully the "true" (avoiding the use of positive here) outcome of a cancer diagnosis or the failure of an engineering machine/structure is much less likely than a "false" outcome. Therefore typically in such cases (particularly in high-stakes or safety-critical systems) there is an imbalance in the sample data.
So assuming we can't easily go and collect more examples of the minority class, then with the existing imbalanced dataset we have two options:
Option 1 we under sample. This involved removing examples of the majority class so that the number is the same as the minority class. This can be done in a naive way by randomly dropping samples, or in a more strategic way using thinning algorithms - for example, see digiLab's work on a method called DaFT (Derivative Free Thinning). Personally, I don't like throwing away data without a really good reason. This involves throwing away data we have made an effort to collect, it contains information about the problem we are trying to solve, so with that why throw it away? Data scientists don't like throwing away data, full stop!
Option 2 we over sample. This involves generating synthetic examples from the minority class so that the number is the same as the majority class. No data was thrown away. Again, the naive way of doing this is to duplicate samples of the minority class. This can work. SMOTE, which stands for Synthetic minority oversampling technique is a bit of a neater classy way of oversampling.
Preparing your training dataset might not be the most exciting part of machine learning technology or deep learning, but is essential if you want to make accurate predictions with a classification algorithm.
The Key Idea - SMOTE for Balancing Data
SMOTE - the Synthetic Minority Oversample Technique - as the name suggests it is an approach to generate new synthetic sample data from the minority class, thereby addressing our class imbalance issue.
The concept uses our old friend k Nearest neighbors (kNN) and a random sampling technique. So let us walk you through the key steps.
So our starting point is we can split our training data into a minority class and a majority class. In the little diagram below, we highlight the minority class as blue dots!
- Randomly sample a data point from the minority class.
- Find the k nearest neighbors to that sample point which also belongs to the minority class.
- Randomly sample one of these nearest neighbors from the same minority class or class label.
- Build a vector ( a line ) between your original sample data point and one of its neighbours you selected in STEP 3.
- Randomly generate a new synthetic example (synthetic instance) somewhere on that line between these two points (by sampling from a uniform distribution - more on that below). Use this new point as a new (synthetic) sample to increase the sample data at training.
This process is then repeated until enough new samples are generated, noting that new synthetic points are not used to spawn new samples.
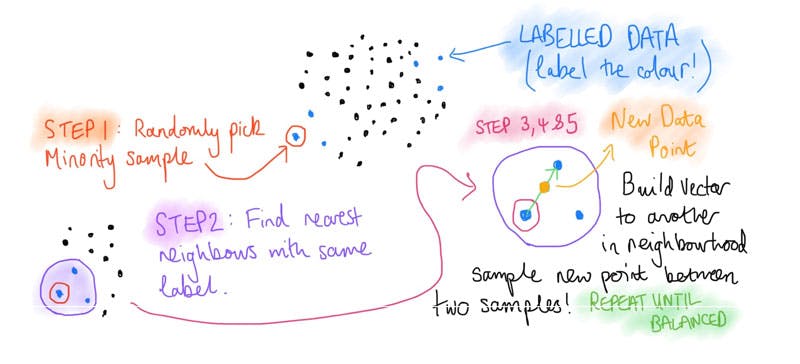
Figure 2 : a visual representation of smote which enables you to over sample an imblanced data set by using generating synthetic examples
Here we consider it in the context of a binary classification dataset where there are only two target classes, but in general the method can be extended to any number of class labels. To do this the process is repeated over all minority classes.
Implementing SMOTE in python
Ok so when I say implementing, I mean finding the right library for the job! Don't go reinventing the wheel, learn the key concepts and then find high-quality, well-tested code which does the job so you can implement quickly. If you are new to machine learning, you can't go far wrong with scikit-learn.
With this advice in mind, there is a really nice python package which is built on top of scikit-learn. In their own words, this is what the package does:
Imbalanced-learn (imported as imblearn) is an open source, MIT-licensed library relying on scikit-learn (imported as sklearn) and provides tools when dealing with classification with imbalanced classes.
Just the ticket, and actually has all the main methods which are used to rebalance your nasty datasets.
So the starting point will be to install the libraries, for me this looks like
pip install imblearn sklearn
If this doesn't mean anything to you, and you aren't sure how to fire up a Python environment to get going, then no sweat. We have built a free course which will get you started - called Getting Started and Python Basics.
Walking through a Minority class - Majority class Imbalance
Here we are just going to demo SMOTE using an imbalanced dataset provided by Kaggle - called the bank churn prediction dataset. In this dataset we have information about customers, which we pick out the numeric values as the inputs (e.g. credit score, age, tenure, balance, along with some others - see below) and our target variable is whether they left (exited) the bank that year, so it is a nice simple binary classification dataset.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
df = pd.read_csv("churn.csv") # Read banking dataset
X = df[['CreditScore', 'Age', 'Tenure', 'Balance', 'NumOfProducts', 'HasCrCard', 'IsActiveMember', 'EstimatedSalary']]
y = df['Exited']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
y.value_counts().plot(kind='bar', color = ["blue", "orange"])
Here we see a total of 10,000 samples with 79.63% not exiting and 20.37% leaving. We perform a splitting over the data, so that we retain 20% for testing. The final line generates a nice little bar chart, reinforcing the imbalance in our dataset.
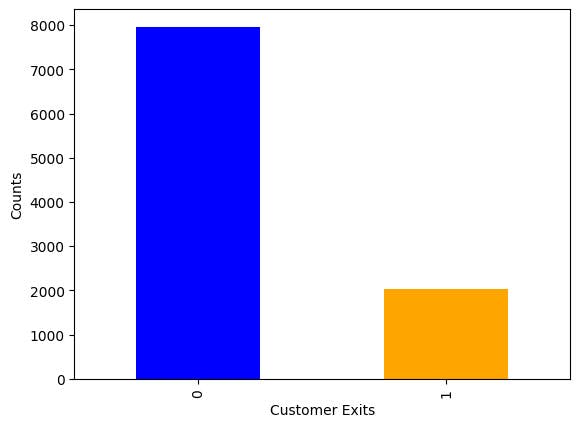
Figure 3 : First look at our imbalanced dataset with 80% : 20% split between the majority class and the minority class
Baseline the Approach
To baseline our approach using SMOTE, let's first build a machine learning model straight from this data and see how we get on. We will also make a common mistake I see all the time from new data science students working on their first imbalanced datasets.
Here is a chance to use my favourite "out the box" machine learning model - XGBoost. But you could try a machine learning model here (e.g. random forest, neural network or logistic regression) - the nice thing about this approach it is also robust to having continuous and categorical features.
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, recall_score
# Make us some test data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# Fit the machine learning algorithm
model = XGBClassifier().fit(X_train, y_train)
# Make predictions over the test data
y_pred = model.predict(X_test)
# Calculate Accuracy and Recall against the test data
accuracy = accuracy_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
print("Recall: %.2f%%" % (recall * 100.0))
So if you get a chance to run this. You might first think that you are done. This bit of code for me spits out an accuracy of around 84.70%, amazing! Or is it ?
Given in the class imbalance in the dataset, our minority class only makes up ~20% of the training data. So a predictive model which simply returns "NO" (which is what this one actually does) would also be correct 80% of the time, so we have done little better than this. So a key take-home message for imbalanced data is not only must we try and rebalance our datasets using machine learning algorithms like SMOTE, but we must be careful about how we define good. We see that any initial delight at 84.70% accuracy is but an illusion.
Various metrics can be used to determine the performance of classification in imbalanced data. Here we validate this model using what we look at in our Foundations in Machine Learning Course and calculate a confusion matrix, from which we use our test data.
from sklearn.metrics import confusion_matrix
conf_mat = confusion_matrix(y_true=y_test, y_pred=y_pred)
This gives us a 2 by 2 matrix, which we can nicely visualise in a plot.
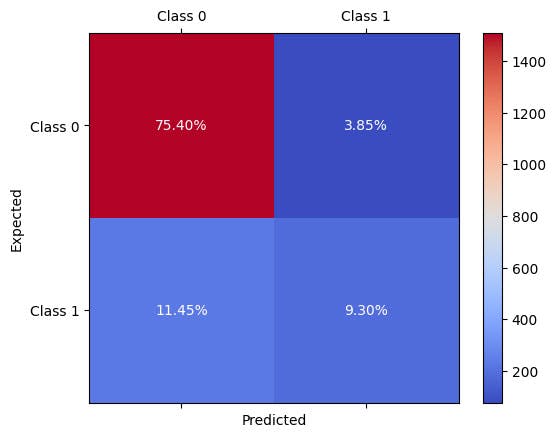
Figure 4 : Confusion matrix used to validate the performance of XGBOOST on the baseline, unbalanced dataset
A confusion matrix basically gives us information on the four possible outcomes for a binary classifier ( can also be used for multi-classification problems).
- The sum of the total numbers gives the total number of samples in the dataset.
- The sum of the diagonal gives the total of correct classification, where the top left are true negatives or TN (those samples correctly classified as negative), whilst the bottom right gives the true positives or TP (those samples correctly classified as positive).
- The off-diagonal terms (i.e. bottom left and top right) are samples which have been wrongly classified. With the bottom left, showing false negatives (or FN) and the top left shows false positives (or FP).
We see that this first model built with an imbalanced dataset actually predicts negative results completely independently of any inputs. A better way to score the accuracy is to look at the percentage of True Positives (TP) over total positives (True Positives (TP) plus False Negatives (FN)) - this is also known as the recall or sensitivity of a classifier, given by the formula
The sensitivity of this first model is , so not the best!
Building a Better Machine Learning Model Using SMOTE
So the point really is we aren't interested in accuracy, as this is of little meaning here, but we want to see if SMOTE particularly improves the model's sensitivity (or recall) over the testing set.
So firstly let's build a more balanced data set using SMOTE.
from imblearn.over_sampling import SMOTE
smote = SMOTE(sampling_strategy="minority")
X_sm, y_sm = smote.fit_resample(X_train, y_train)
y_sm.value_counts().plot(kind='bar', color = ["blue", "orange"])
So now the balance of our minority class or majority class for the training set is balanced.
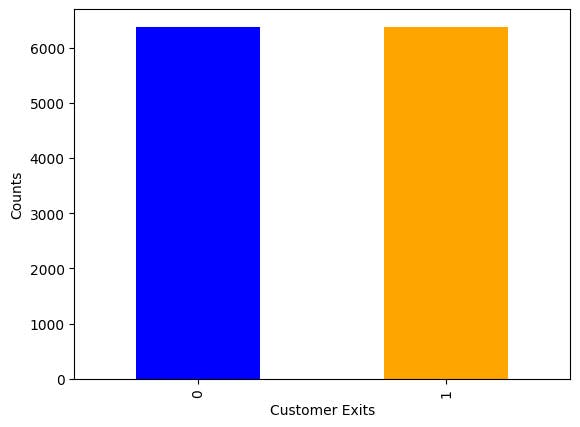
Figure 5 : Quick visual check that after using smote, enough synthetic examples have been generated to level up our unbalanced dataset
Note there are only just over 6,000 samples in each, this is because SMOTE is only applied to the training set, where 20% of the original data set was held back for testing data.
We are now in a position to fit the same model as our baseline and make a comparison.
model_new = XGBClassifier().fit(X_sm, y_sm)
y_pred = model_new.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
print("Recall or Sensitivity: %.2f%%" % (recall * 100.0))
Before comparing results against the baseline, let's first have a look at the confusion matrix for the new model over our test data.
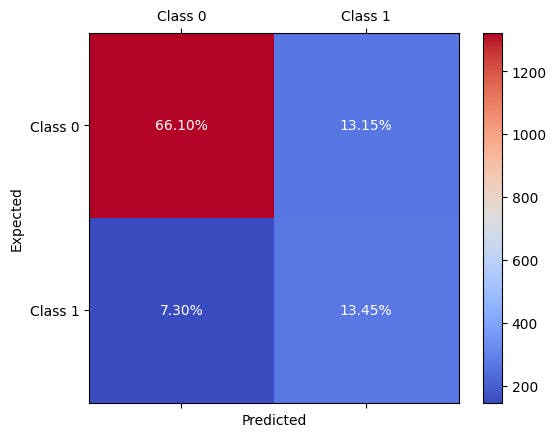
Figure 6 : Confusion matrix to explore xgboost's performance after using smote
From these results, we can make a comparison with the baseline which we summarise in the table of results below.
| Accuracy | Recall | Precision | |
|---|---|---|---|
| Baseline | 84.70% | 44.82% | 70.72% |
| SMOTE | 79.55% | 63.61% | 50.57% |
Here as discussed in an imbalanced testing set, the accuracy has little information on model performance, it actually slightly drops. However, the most important thing is we see an increase in recall from 44.82% to 63.61% a significant increase.
Whilst the results are not perfect (yet) we see that SMOTE has clearly reduced the number of false negatives and accuracy of picking up the minority class.
How effective is SMOTE?
The answer here is not particularly satisfying! It depends. If the class boundary between the majority and minority class is complex, then most machine learning algorithms which seek to address unbalanced data will struggle. In this case there the primary way to improve sampling is to collect more data, targeted at the minority class. This becomes a form of semi-supervised learning, for which statistical methods can greatly improve data quality.
Concluding Points
SMOTE is just one of a few machine learning techniques that can be used to address the problem of having an unbalanced dataset when faced with a classification problem in a data science challenge. It would be generating new data points (or synthetic samples) in the neighbour in between existing known samples which also hold the minority class label.
The really nice python library (Imbalanced-learn) which sits aside scikit-learn, allows us to easy try out smote and other rebalancing methods, often with just a few changes in your code. Here is a list of the eight over sampling techniques that can be used out the box - most of which are slight variations on smote.
How well smote improves the performance (focusing here on the recall or sensitivity) really depends on the problem. If the class boundary, between minority and majority class labels is complex then any approach will struggle to improve classification algorithm performance.
Learning how to handle and validate an imbalanced dataset is an essential bit of knowledge discovery required for budding data scientists. So why not try it out on your own data set or problem, and use it alongside your favourite machine learning algorithms be a linear regression, random forest or artificial neural networks.
References
The original SMOTE algorithm was published in the Journal of Artificial Intelligence back in 2002. If you fancy getting more of the origins of this method, here is the reference and a link to an open-source version of the paper https://arxiv.org/abs/1106.1813
N. V. Chawla, K. W. Bowyer, L. O. Hall, W. P. Kegelmeyer, “SMOTE: synthetic minority over-sampling technique,” Journal of artificial intelligence research, 321-357, 2002.
Featured Posts
If you found this post helpful, you might enjoy some of these other news updates.
Python In Excel, What Impact Will It Have?
Exploring the likely uses and limitations of Python in Excel

Richard Warburton
Large Scale Uncertainty Quantification
Large Scale Uncertainty Quantification: UM-Bridge makes it easy!

Dr Mikkel Lykkegaard
Expanding our AI Data Assistant to use Prompt Templates and Chains
Part 2 - Using prompt templates, chains and tools to supercharge our assistant's capabilities

Dr Ana Rojo-Echeburúa