![[object Object]](/_next/image?url=https%3A%2F%2Fcdn.sanity.io%2Fimages%2Fei1axngy%2Fproduction%2Ff83f8e24d1fb84d1211763941d7874ed6b2a2da8-281x285.jpg&w=256&q=75)
by Prof Tim Dodwell
Updated 20 April 2023
What is the Curse of Dimensionality in Machine Learning?
![[object Object]](/_next/image?url=https%3A%2F%2Fcdn.sanity.io%2Fimages%2Fei1axngy%2Fproduction%2F67cdf3b41441701e313ab892cc1d6bd437bed6c0-1456x816.jpg&w=2048&q=75)
If you have ever dipped your toe into the world of Machine Learning, then chances are that you have come across the term the "Curse of Dimensionality". It sounds ominous, doesn't it? In this blog post, we'll explore why the Curse of Dimensionality is an important concept in Machine Learning and Data Science, how it shapes our understanding of how we should collect data and the types of machine learning models we select for different tasks.
The Curse of Dimensionality and Generalisation
For me, a machine learning algorithm's ability to generalise to unseen data is the most important aspect of building good models. This predictive power comes when an ML model starts to display what we might align with "artificial intelligence", rather than a simple look up table of existing data, patterns have been established where new predictions and (potentially) insights can be drawn.
We want a model which is sufficiently expressive, with sufficient inputs to capture complex patterns and relationships within the data. This means often being able to express a large number of inputs (information about the system) and having highly parameterised models which are flexible enough to capture lots of different behaviours.
In simple terms, the Curse of Dimensionality refers to the fact that as the number of features (or dimensions) in a dataset increases, the amount of data required to cover the feature space increases exponentially. This means that as the dimensions increase (models with large numbers of inputs and parameters) it becomes increasingly difficult to find patterns in the data. In other words, most points in a high-dimensional space are very far apart from each other - much further than we would expect in lower-dimensional spaces.
There is a very interesting phenomenon called the Hughes phenomenon which states that for a fixed size dataset the performance of a ML model decreases as the dimensionality increases.
Space filling - Everything is along way apart in high dimensions.
Suppose we have a one dimensional input space, which takes values between and . We ask for three equally space data points, so that the distance between each data point is just . In two dimensions, the number of data points required to keep the same distance apart is points.
In much higher dimensions, say 100 (not a big problem for ML) then the number of samples I need to retain a the distance of between each point is .
This is an eye watering amount of training data, even for the above example where the dimension of the input space is still relatively small.
Let's think about a common machine learning problem, in which images are classified. For example the classic questions, "Is this picture, a picture of a Cat?" a classic supervised (classification) problem. Take for an example a picture made up of by pixels, in which each pixel is represented by color values - Red, Green, Blue (RGB).
This gives a total input dimension of values.
Data Sparsity - Perfect Conditions for Overfitting
This means that even if we have alot of data, for high dimensional problems the data is almost always sparse. As a result in ML we are often in the regime of limited data and highly parameterised models. A gold star example of this is a neural network. These two ingredients together give the perfect conditions for overfitting.
Overfitting is where a machine learning model perfectly fits the training samples, yet does not generalise to validation data which is unseen during training. As a result, by definition overfitted models do not generalise well.
It is hard to visualise overfitting in higher dimensions. But here for a simple example, with fixed data points (green dots below), we can increase the order of the polynomial from (shown on the left below) to (showed on the right).
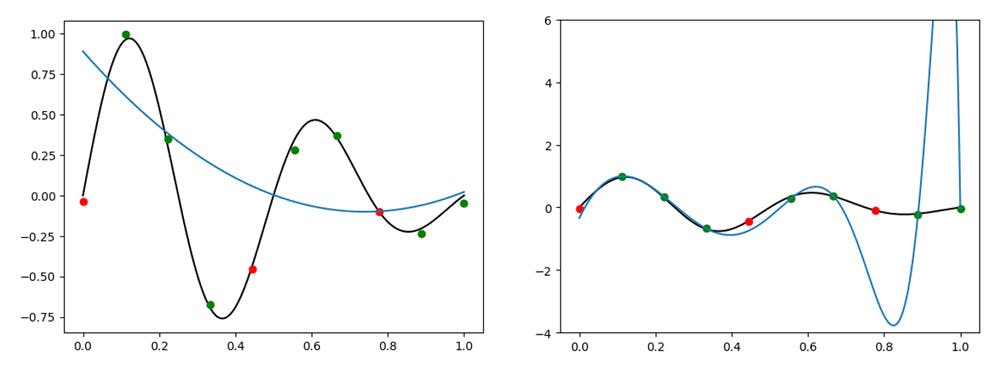
Fitting of Data using 3rd order (left) and 25-order (right) polynomials. Examples of under and overfitting of the data respectively
On the left, for the lower order model, we see an example of underfitting. The prediction (shown in blue) captures only the overall decreasing trend, and not the oscillations in the data. On the other hand as we increase the order of the polynomial to , as shown on the right hand side, we show good fitting against the training data points shown in green, but very poor generalisation to the validation points shown in red. This right hand example is a good demonstration of overfitting.
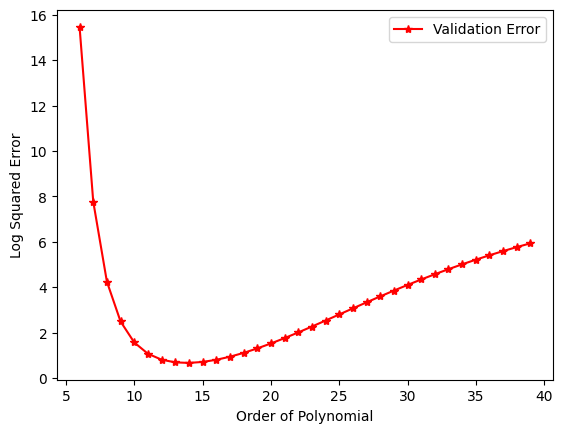
Figure 2 : Here we show a plot of validation error against polynomial order we see that a good choice of polynomial order is 12 - 15
What you see here is a plot of order of polynomial against validation loss. This is the loss function evaluated on a held out data set. Validation loss (evaluated on random points held out prior to training) We see that for small polynomial order their validation loss is high, this represents the under-fitting regime. On the other hand for very large order of polynomial, we see increasing model performance, as we move into the over-fitting regime. A good choice of polynomial order in this case is 12 - 15.
Building Good ML models is as much an Art as it is a Science
There are fundamental techniques which can be used to overcome these pathological challenges caused by the Curse of Dimensionality. The easiest solution to suggest is to collect more training data. But as we see in the example, huge amounts more data are required to effectively fill high dimensional space, and often further data acquisition is not simple.
Dimension reduction techniques
Often Dimension Reduction Techniques, which are a sub-class of unsupervised learning methods, are used which help to reduce the dimensionality of data representation while still preserving (at least most of) the vital information in the data. This process is often called feature extraction.
When it comes to writing down ML models the inputs of a model, be it image data or streaming data from a sensor, are represented as a vector. High dimensional data means this data is represented by a large vector - in our picture below where denotes the dimension.
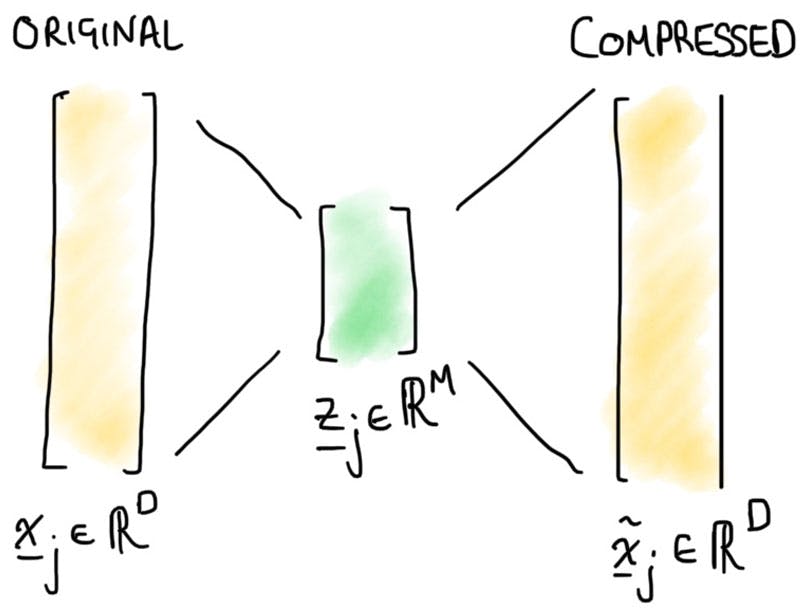
Figure 3 : Sketch representation showing compression and reconstruction, into and out of a latent representation or feature space
The core idea is to map our data set into a set of much lower dimensional variables, in the picture example above, we show this reduction of input parameters to feature variable. The feature values are then stored in a vector of reduced size , often referred to as the latent space. In machine learning models this process is often called encoding, whilst the reverse of this process is referred to as decoding. Decoding is the reconstruction from fewer features in this latent space back into the high dimensional data representation.
There are various widely used techniques including principal component analysis (PCA), Autoencoders and t-SNE (t-Distributed Stochastic Neighbour Embedding). Let's briefly consider the first, since finding the principal components in the data set is both simple and can be done with little computational efforts required.
Principal Component Analysis
Principal Component Analysis (aka PCA) is a linear dimension reduction method, since components of the new representation or reduced representation are linear combinations of the full representation . Therefore the encoding and decoding steps can be represented by matrix operations (which we visualise below)
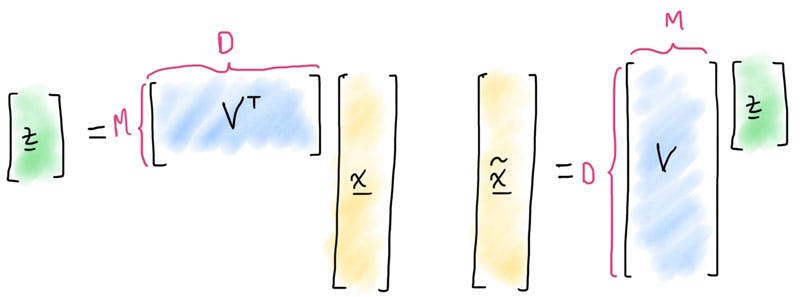
Figure 4 : Representation of the Linear Operations which project the high-dimensional space into the latent feature space, and then back
Let's not worry too much about the maths (if you would like to unpick this more, have a look at my From Zero to Sixty : Foundations in ML course on the academy), however how this dimension reduction is achieved is by determining the each of the columns of the matrix.
The key idea in principal component analyse is that we pick the columns (which we can write ) such that we
-
Choose directions so capture maximum variance of the original data set .
-
Choose coloumns and so they are ortogonal (at 90 degrees to each other).
To visualise what this looks like on a simple data two dimensional data set, we see two principle components. The principle component pointing the direction of the greatest variance, and the second component orthogonal (i.e. at 90 degrees to the first).
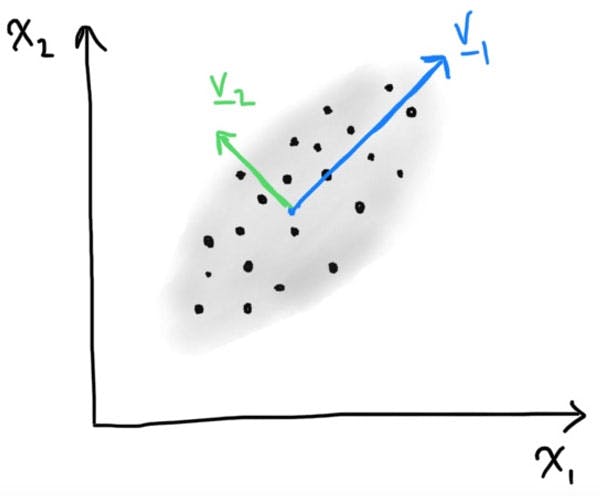
Figure 5 : Simple, made up data set showing a two dimnesion example, and geometric interpretation of the principal components
In this simple example we see that projecting our data into a single feature variable aligned with the first principal component, we will capture most the variation in the data and reduce the dimension from 2 to 1.
A simple code example in sklearn
Implementing PCA in sklearn couldn't be easier, here is an example have a go yourself.
from sklearn.decomposition import PCA
import numpy as np
# Dumpy data set.
X = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# Create a PCA object with 2 components
pca = PCA(n_components=2)
# Fit the PCA model to the data
pca.fit(X)
# Transform the data to its principal components
z = pca.transform(X)
# Print the original and transformed data
print("Original data:\n", X)
print("Transformed data:\n", z)
Why not try it out on one of your data science projects?
Regularization
Often alongside dimension reduction, regularisation plays a key role in overcoming the curse of dimensionality. Just like dimension reduction, it is a big topic, we won’t (or can’t cover it all here). But here are the main principles.
So let’s jump back to the example of fitting the polynomial model above. With polynomial fitting, you have this nice handle you can play with the order of the polynomial. But this also means that if you pick a model with (order of the polynomial), you have all terms in the polynomial of lower order than as well. So this model is often overly expressive for no reason. To express data points well, I don’t typically need polynomials with order 16 and 18 powers of as they have similar characteristics.
A bit of math (for those that want it!)
So suppose that we have a parameterised machine learning model, where . We typically want to find the parameters which minimise a loss function. A loss function is a measure of how well a model fits the training data, where a loss of zero represents perfect reconstruction of the training data. Regularisation works by introducing an additional term to the loss function, so that if we have a training dataset of labelled data , then the loss over this training set is
So let us unpack this a little. So in this equation, the first term is the Mean-squared loss term of the model to be fitted and the data, the new or additional term is , where
The parameter , a number to be set, defines the relative importance between the regularisation term and the model fit or error. So this becomes another parameter we have to tune (aka a hyper parameter).
In statistics, this method is often called the shrinkage approach. This is because becomes large when any of the parameters come large. Therefore if any term does not contribute to reducing the error, then it will be shrunk to zero, hence helping reduce the second term , but with little or no increase in the fitting of the model.
This special choice of (quadratic) regularisation term is called ridge regression, or in neural networks referred to as weight decay.
This approach has a similar effect to dimension reduction, and helps with the curse of dimensionality as provides penalty to the number of active terms you have in your model. By having less terms, you can been exponential reduce you data requirements; yet still have good models which are robust in high dimensions.
Feature Engineering
The parameter , a number to be set, defines the relative importance between the regularisation term and the model fit or error. So this becomes another parameter we have to tune (aka a hyper parameter).
In statistics, this method is often called the shrinkage approach. This is because becomes large when any of the parameters come large. Therefore if any term does not contribute to reducing the error, then it will be shrunk to zero, hence helping reduce the second term , but with little or no increase in the fitting of the model.
This special choice of (quadratic) regularisation term is called ridge regression, or in neural networks referred to as weight decay.
This approach has a similar effect to dimension reduction and helps with the curse of dimensionality as it provides a penalty to the number of active terms you have in your model. By having fewer terms, you can exponentially reduce your data requirements; yet still have good models which are robust in high dimensions.
Living with the Curse of Dimensionality
So there you have it - the Curse of Dimensionality is not something to be feared, but rather something to embrace, it is one constant in ML. By understanding the fundamental properties of high-dimensional spaces and having smart techniques like dimensionality reduction techniques, regularisation and feature selection at your disposal you will be in a good position!
If you are an aspiring data scientist or ML specialist then it is vital to have a deep understanding of these concepts in order to make informed decisions about how to approach ML projects in your business and be able to foresee the early pitfalls you might come across in with complex large scale data sets and models.
An introduction to dimension reduction methods, alongside other unsupervised learning, as well as examples showing feature engineering examples in the wild can be found as part of the From Zero to Sixty: Foundations in Machine Learning course.
Featured Posts
If you found this post helpful, you might enjoy some of these other news updates.
Python In Excel, What Impact Will It Have?
Exploring the likely uses and limitations of Python in Excel

Richard Warburton
Large Scale Uncertainty Quantification
Large Scale Uncertainty Quantification: UM-Bridge makes it easy!

Dr Mikkel Lykkegaard
Expanding our AI Data Assistant to use Prompt Templates and Chains
Part 2 - Using prompt templates, chains and tools to supercharge our assistant's capabilities

Dr Ana Rojo-Echeburúa